NV Teh
Obrt za informatičke usluge
Many of us are so used to working on a computer desktop that when the time comes to purchase a new computer, we don’t consider other options.
Many of us are so used to working on a computer desktop that when the time comes to purchase a new computer, we don’t consider other options.
TL;DR Creating public (unencrypted) EBS Snapshots might not be a great idea. Even if you are going to share them “just for a second”. A lot can be fished out of these snapshots: ssh keys, tls/ssl certificates, aws credentials, private source code and internal (extremely) valuable HR/Accounting/IT documents.
DISCLAIMER: We did our best to inform the companies we were able to identify as potential owners of the problematic data. Since the misuse of EBS snapshots happens daily we believe that hiding the fact will do more damage than exposing the problem. Especially since we believe we are probably not the first nor the only ones who have noticed the problem. Thus, we have decided to give a talk and write a blog post about the problem in the hope that it will create enough traction to warn AWS users to be extra careful when creating public EBS snapshots.
This post is a follow up and a summary of the talk we gave at the 2017 DORS/CLUC conference about our experiences with the cloud and big-game fishing in IT. We know, it sounds weird, doesn’t it? Please do excuse us if we make this post a bit funny and sarcastic although we are aware that the consequences of sharing private data are often tedious.
We are now ready to start with the story. Once upon a time there were consultants ...
As consultants for cloud solutions we are often asked to help our clients in developing, deploying and reviewing IT solutions. One of the most common requests is to review client’s internal policies and implementations regarding data and code protection and this is almost always based on the client’s fear of storing data in the cloud. In AWS terms you can think of S3, EBS, Glacier as these “places” for sharing, archiving or backing up data in the cloud.
The benefits of reviewing processes and code for clients are numerous, of course, but what we really value are insights we get in all the different ways companies can misuse best practices. We value these insights because they help us to develop tools and standard operating procedures (SOPs) about how to avoid common mistakes as a part of our R&D department routine. We are especially interested in the ways that clients can (or do) avoid best practices (often very time consuming) to gain efficiency. Over the past few years this research resulted in some of the funniest and scariest IT work we have done. In this post we would like to share one of the amazing ways in which everyday IT professionals and companies misuse AWS services.
For readers not familiar with AWS we will first introduce a few key services (components) of AWS cloud solutions for storage, namely, Elastic Block Store (EBS) and EBS snapshots. If you are an AWS veteran you can skip the following (introductory) section.
AWS Elastic Block Store is a service that provides highly available block level storage volumes for use with Amazon EC2 instances. Think of it as virtual hard-disks available on-demand. EBS is the oldest persistent block storage available to EC2 instances (think of virtual servers) and thus it is an excellent choice for applications like databases, operating systems, etc.
The concrete “virtual hard-disk” you connect to your Amazon EC2 instance is known as an EBS volume. EBS volumes differ in speed, size and other options. Especially useful is the option to encrypt volumes.
EBS volumes, like all volumes/disks, can benefit from a good backup system and this system in AWS is called EBS snapshots. An EBS snapshot is a point-in-time backup of your EBS volume. It is a “copy” of the data on your EBS volume, ideal to make copies of your disks, share them or as a classical disaster-recovery solution. If you want to backup the data from your EC2 instance, then you probably want to create EBS snapshots of the EBS volumes attached to the instance. Users with appropriate access can afterwards copy your snapshot and create their own EBS volumes based on your snapshot, while your original snapshot remains unaffected.
Since EBS snapshots are simple to use, easy to recover and (most of the time) fast, they seem like the perfect way to share data. Amazon was obviously aware of the benefits of using EBS snapshots so included functionality to share snapshots among users. Nowadays, you can share snapshots with other accounts by adding their AWS IDs to an appropriate place in the web console. Anddddd, you can share snapshots publicly.
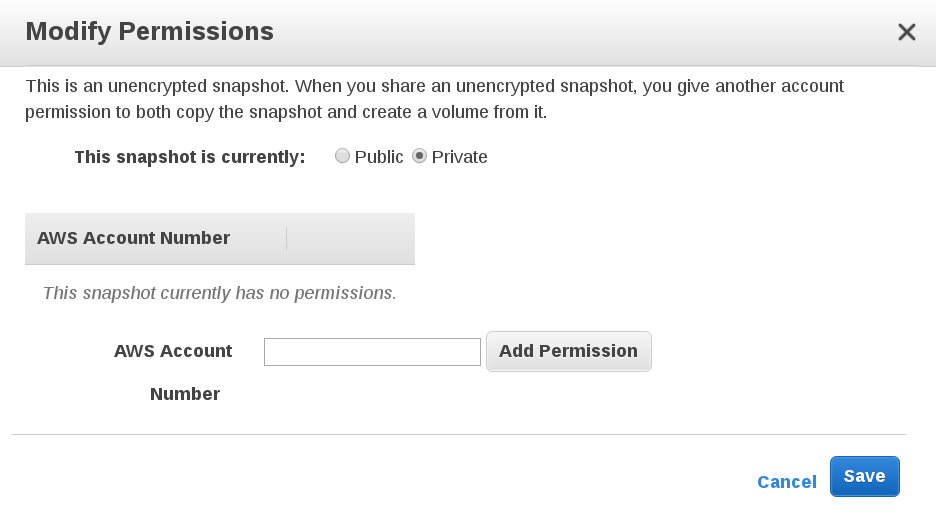
We believe there are good reasons why Amazon decided to have the option to create public snapshots easily accessible to users. Nevertheless, they were obviously aware that this option might lead to problems and thus made the following comment in their official documentation:

As you have probably already guessed, we decided to exploit the possibility of sharing EBS snapshots publicly. Our team at R&D are always exploring the features and quirks of AWS and so had the perfect excuse to go on a “fishing” trip. Is there a better way to spend “holidays” with friends than to enjoy the beauties of easily accessible data on AWS? You never know what you might catch :)

It is important to say that the decision to go on a fishing trip was not completely out of the blue. We were fully aware that sharing EBS snapshots publicly does not seem like a good idea and thus we thought that this is obvious to everyone. In this case, the fishing trip seemed like a waste of time. That is, until the day a client came to our office and asked us to take a look at their AWS infrastructure and underlying processes.
The first thing we noticed was that they were sharing snapshots for a local Jenkins instance publicly. It made sense to them as they needed to make copies of the data and transfer it to a non-AWS location. As the client explained to us, “in the end who will find it in the enormous AWS cloud”. To make it easier for them, they also used “Jenkins” as a term in the description of the snapshot. In other words, the client did everything to help others find the data.
All of a sudden the fishing trip seemed like a plausible thing to do. We just had to prepare ourselves. Firstly, we had to go through all the regions and search for publicly available snapshots containing words that could indicate an EBS snapshot with a lot of (interesting) data. “Jenkins” was obviously the first word. The second (even more obvious) was “backup”.

With just the terms “jenkins” and “backup” we found more than 30 snapshots publicly available throughout different regions. So the question now was, are there more?
An obvious next step was to try other words, or even better, to write a program that would track EBS snapshots and filter them based on predefined words. Ideally, a program would push notifications about new EBS snapshots to our internal chat channel.

Writing such a program was not a problem since AWS has some really neat functions behind it. On the other hand, the problem was that we were now tracking a lot of snapshots. And perhaps more problematic (and interesting) was that we noticed some of these snapshots were available only for a minute or two. Like someone thought he could (without consequences) make the snapshots public just to copy them and make them private again without anyone noticing. This observation prompted us to bring additional tools to the fishing trip. We adjusted the program to create volumes out of these temporary snapshots as soon as they became available/public.
Since this, again, increased the number of snapshots to track and check, yet another automation was needed. Using a set of rules and a bit of AI (artificial intelligence -- yes, nowadays everyone tries to use it everywhere. How hipsterish of us!) we have developed a system that can mark a snapshot with a score from 0 (not interesting at all) to 100 (there is definitely something there). For example, if the system found ssh keys in the snapshot, that snapshot would get a high score.
Finally, we were ready to go fishing :)
By automating our searches we were able to trawl huge numbers of EBS snapshots. Going through the files from different snapshots we had found was indeed cumbersome. But it was also fun. As with fishing, you never know what you’re going to catch on your trawl.:
Genome sequences. This finding might not seem to be special if you are not familiar with patient data protection laws/acts. Genome sequences should not be (in most countries) publicly shared if they contain sequences from humans. Especially if an individual human can be identified based on these sequences. However, what we found in public snapshots were sequences from different organisms (including humans). The funny thing is that these snapshots were owned by some of the best-ranked US universities and they were online for only a few minutes. Obviously, someone thought they should not be publicly shared but made them public just for a second or two to copy something.

Web server configurations (TLS/SSL certificates). Web server configurations by themselves might not be that problematic but when you add an SSL certificate to the story it becomes quite cumbersome. A perfect way to initiate MITM attacks for someone with questionable intentions. This example highlights one of the most common problems with best practices. Sometimes it is simply easier or faster to skip them and use quick solutions (no proxies, not using ELB/ALB services, etc.). Unfortunately, in the end this approach will probably lead to problems. For example, one of the sites whose data was publicly shared on the AWS was actually hacked in the end (and still has its website title changed to the following message). It is difficult to tell whether this was due to having a public snapshot. Nevertheless, it indicates that best practices were probably avoided in other IT procedures too.
SSH keys. Sometimes it seems like a good idea to keep SSH keys on your Jenkins instance. Especially since you often need to pull code from central repositories to the instance. However, to keep keys of your backup servers and on-premises infrastructure is probably not something you would like to do. And yet, some do exactly that.
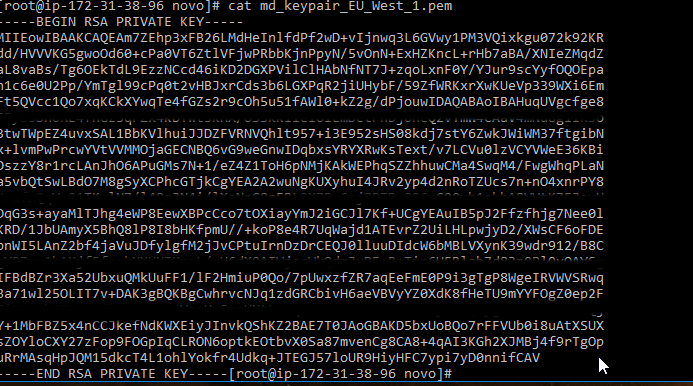
AWS security credentials/API access keys. You know how AWS always talks about roles and how superior they are to access keys when an EC2 instance needs to access something on AWS. Well, some people still do not know about roles. Bad marketing from AWS maybe? Or just plain ignorance? In the end, why should they go through the documentation (or even pass a basic AWS Solutions Architect Associate exam where roles are mentioned multiple times) when they can deploy their keys on EC2 instances. And make snapshots of these machines. And make these snapshots public. Or to make it even more interesting, why should they avoid pushing their partner's keys to the EC2 instance also? And edit home/.aws/credentials to give meaningful and identifiable names to profiles? I suppose when you are a Fortune 100 company (as one was) you will always have enough money to correct for misuses of best practices. We are exaggerating a bit, of course. To leave the snapshot with this data open was probably just a (normal) human error. It happens as you can see throughout this post. But the way the infrastructure was laid out indicates a bigger problem. A problem that illustrates the IT department is not functioning as well as it should. No SOPs perhaps? Generous user permissions? Insufficient user education/training?
Source code of your most valuable (proprietary) applications. CI/CD tools are really amazing achievements in modern software development/management. However, if you leave them open (e.g., create a public snapshot) they will probably shoot you in the foot. After all, these snapshots contain most of your code. The code you were working on for so long and the one competition should not know about. What if your code was shared by a partner for whom you are building this application? You wouldn’t know if the partner was trying to sell it/give it to someone else or just made an error.
A combination of the above. There was a snapshot that contained source code for private applications together with AWS and SSH keys. Practically, everything you need to ruin a company's life. And it was shared between two companies, a Fortune 100 company and its smaller partner.
Yep, we caught a monster. You know, one of those monster catfish everyone talks about but almost no one ever saw (except on the internets). The one that covers all the expenses and hard work and makes you a level 9999 fisherman instantly.
So what is this monster fish? Believe it or not, hidden in the AWS cloud there was a publicly (ok, not so hidden then) accessible backup of a disk from a decently-sized company in the EU with a huge appetite for growth. A snapshot with 1 terabyte of documents from various departments (including Finances, HR, IT, ...). At first we thought, okay, not convinced that there is something special there. Probably just Gantt charts and a few bills. But as we started to dive into folders, files, … we have stumbled upon things like

Definitely a good catch. Especially since the data was not from some random company. The data was from a company worth millions (in euros) with an excellent reputation in offering IT services. It seems that the big wigs can also make (big) mistakes.
Still not convinced this was a monster fish from fairy tales? Maybe this list of interesting directories might help to convince you. If a company lost this sort of data from May 2018 onwards, the fines under the incoming GDPR legislation could be up to 4% annual turnover.

So what to do with all the beauties we have found/caught? Less charitable types than us might sell it on a black market/deep web or whatever the catchphrase is at the moment. Instead we tried to deduce who is the rightful owner of these snapshots and to warn them.
The biggest problem with deducing whom you should contact is that the only thing you have about a snapshot is its ID. There is no information on the owner of that snapshot. And the snapshot doesn’t even have to belong to its rightful owner since someone else might have caught a public snapshot that was available for a few moments, made a volume/snapshot out of it and is now publicly sharing that snapshot. Thus, it seems that probably the best way to identify the owner is to go through the files manually and try to guess whom they belong to.
With some snapshots the job was easy. Some files had headers with the company’s logo or information on them. While for others we had to dive deeper and check for email addresses, code authors and similar.
When we finally believed we knew who the rightful owner is, we decided to contact them. By sending emails, of course, but without disclosing what we have found in the email itself. Ideally, we proposed, we should have a teleconference (TC) with company representatives to see if a snapshot/data really belongs to them. After all, we do not want to give someone else’s data to whom it does not belong.
Most of the companies did reply that they would like to have a TC and most of them replied within an hour. So we agreed on having a TC immediately. The funny thing is that almost all of the companies started the TC with a casual and carefree attitude. Probably thinking that we have found something of low impact. Until we showed them what exactly was the problem. After that you could see a rapid change in their facial expressions. The TCs were finished soon after the disclosure and the representatives promised that they will get back to us as soon as they pinpoint the origin of the problem.
Here are some of the interesting replies afterwards: a Fortune 100 company replied with “we’ve readied our media team to reduce the potential impact of the finding if you are going to go public with it”; another one with “we’ll have to call for a board of directors meeting to discuss it”; we also had “this might ruin us completely”; “when do you plan to publish your post so we can prepare ourselves” and “it was not our fault, it was our partner’s fault”.
It was also interesting to notice that a Fortune 500 company (not the Fortune 100 one) did not reply at all to the our emails. Thus, we have had no TCs with them. We thought, okay, this must be the reason why they are not reaching the Fortune 100 level. (sarcasm sign) → ؟
It seems that some companies simply do not care about what they leave open to the public while some simply ignore e-mails other companies send them. And some e-mails should not be ignored. For example, if someone writes you an email saying that they found a flaw in your system and is offering (free!) help we suppose a smart thing to do would be to at least accept his proposal. Especially if he found something that could be quite embarrassing to you or your company.
The funny thing is that we didn’t falsely cry shark three times before. It definitely was a fish that could bite your hand off, every time!
Unfortunately, since these companies were not nimble enough to reply to our emails their data is still publicly accessible. The “do-not-reply” approach might be completely understandable if these companies published their data to the public on purpose and do not have time to tackle with minions like us, but on the other hand, a not so smart thing to do if they did not have the intention to share the data. Either way, we did our best and were kind enough to warn them.
Although they probably deserve to be publicly named as a measure of precaution for their clients, we will not publicly disclose the names of these companies since we believe that any interested reader (and AWS user) will probably have no problems in figuring out who they are. After all, the data is still somewhere in the public (AWS) domain, accessible to all (AWS users) and could be a perfect way to spend an afternoon playing Capture the flag (CTF).
It was a long read, we know, so we will try to keep this (last) part short.
As you might have noticed the main problem emphasized in this post was not the cloud itself, the problem was the avoidance of best practices. Be it “read the documentation” or “do all you can to protect your assets (data)” it seems that users will always find a way to avoid them and if nothing (bad) happens the survivorship bias will kick in resulting in future misuses. However, not everyone will be lucky enough to stay unpunished for ignoring best practices, as can be seen from this post.
Just within one of the affected companies, in the first few weeks of the incident, more than 100 man days of effort have been attributed to the issue and significant costs were incurred (in tens of thousands of euro).
The amazing fact is that all the problems with public snapshots described here would have been avoided if companies had a simple rule: encrypt the snapshots you use! Even if you accidentally create a public EBS snapshot only users with appropriate encryption/decryption keys will be able to use it. Additionally, you should share snapshots with sensitive data only with the people you trust. The last one should be obvious to everyone but, as shown here, for some reason it is not.
It is important to stress that AWS adds so many services so quickly that if a company's cloud advisors don’t have an R&D team they are going to be left behind soon. Not understanding the details of the services you are using (e.g., benefits of encryption), not realising the full potential of API calls (e.g., the ease with which you can list and track snapshots) or that a single individual with too generous user permissions can upload an entire organisations structure to a public site will lead to problems. Thus, you should fully understand the complex services you are using prior to pushing them to production.
If you or your company were creating public snapshots with private data you should conduct a rigorous review of resources deployed in Amazon AWS and the associated process and procedures around data protection. If you think your data might have been accessed by a third party you should classify the affected information and should prepare notification for the affected parties and associated authorities/regulatory (data protection) agencies. If not, good for you!
We sincerely hope this post will raise awareness on the issue and that we will help some of you to improve processes to do with data security across your business.


